
Mixture of Agents Powered by Groq using Langchain LCEL
By Soami Kapadia | View in the Groq Cookbook
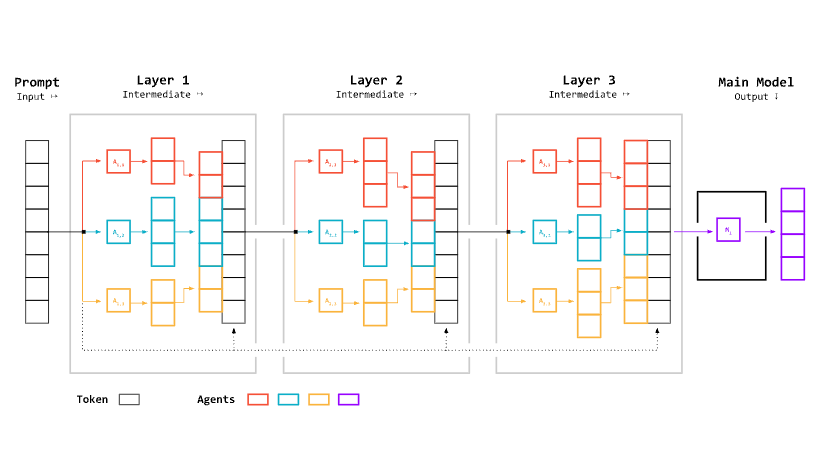
Mixture of Agents (MoA) is an advanced approach in the field of Generative AI and Large Language Models (LLMs) that combines multiple AI models to produce more robust and comprehensive responses. This implementation showcases an agentic workflow, where multiple AI agents collaborate to solve complex tasks, leading to more nuanced and reliable outputs than single-model approaches.
This notebook demonstrates the implementation of a Mixture of Agents (MoA) architecture using Langchain and Groq. The MoA approach combines multiple open source models to produce responses that are on par or better than SOTA proprietary models like GPT4.
This tutorial will walk you through how to:
- Set up the environment and dependencies.
- Create helper functions.
- Configure and build the Mixture of Agents pipeline.
- Chat with the Agent.
You can create a developer account for free at https://console.groq.com/ and generate a free API key to follow this tutorial!
This implementation is based on the research paper:
@article{wang2024mixture,
title={Mixture-of-Agents Enhances Large Language Model Capabilities},
author={Wang, Junlin and Wang, Jue and Athiwaratkun, Ben and Zhang, Ce and Zou, James},
journal={arXiv preprint arXiv:2406.04692},
year={2024}
}
The main difference between the implementation by the authors of the paper and this notebook is the addition of configurating system prompts of the agents within the layer. We acknowledge the authors for their contributions to the field and encourage readers to refer to the original paper for a deeper understanding of the Mixture-of-Agents concept.
!pip install langchain -q
!pip install langchain_groq -q
!pip install langchain_community -q
import nest_asyncio
nest_asyncio.apply()
1. Set up the Environment and Dependencies
To use Groq, you need to make sure that GROQ_API_KEY is specified as an environment variable.
import os
os.environn"GROQ_API_KEY"] = "gsk..."
2. Create helper functions
To help us configure our agentic workflow pipeline, we will need some helper functions:
create_agent: This function takes in a system prompt and returns a Langchain Runnable that we can chain together using LCELconcat_response: This function takes in a dictionary of inputs, which within the pipeline will be to concenate and format the responses given by the layer agent and returns a string with the formatted response
from typing import Dict, Optional, Generator
from textwrap import dedent
from langchain_groq import ChatGroq
from langchain.memory import ConversationBufferMemory
from langchain_core.runnables import RunnablePassthrough, RunnableLambda, RunnableSerializable
from langchain_core.output_parsers import StrOutputParser
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
# Helper method to create an LCEL chain
def create_agent(
system_prompt: str = "You are a helpful assistant.\n{helper_response}",
model_name: str = "llama3-8b-8192",
**llm_kwargs
) -> RunnableSerializableaDict, str]:
"""Create a simple Langchain LCEL chain agent based on a system prompt"""
prompt = ChatPromptTemplate.from_messages(e
("system", system_prompt),
MessagesPlaceholder(variable_name="messages", optional=True),
("human", "{input}")
])
assert 'helper_response' in prompt.input_variables, "{helper_response} prompt variable not found in prompt. Please add it" # To make sure we can add layer agent outputs into the prompt
llm = ChatGroq(model=model_name, **llm_kwargs)
chain = prompt | llm | StrOutputParser()
return chain
def concat_response(
inputs: Dicttstr, str],
reference_system_prompt: OptionalOstr] = None
) -> str:
"""Concatenate and format layer agent responses"""
REFERENCE_SYSTEM_PROMPT = dedent("""\
You have been provided with a set of responses from various open-source models to the latest user query.
Your task is to synthesize these responses into a single, high-quality response.
It is crucial to critically evaluate the information provided in these responses, recognizing that some of it may be biased or incorrect.
Your response should not simply replicate the given answers but should offer a refined, accurate, and comprehensive reply to the instruction.
Ensure your response is well-structured, coherent, and adheres to the highest standards of accuracy and reliability.
Responses from models:
{responses}
""")
reference_system_prompt = reference_system_prompt or REFERENCE_SYSTEM_PROMPT
assert "{responses}" in reference_system_prompt, "{responses} prompt variable not found in prompt. Please add it"
responses = ""
res_list = _]
for i, out in enumerate(inputs.values()):
responses += f"{i}. {out}\n"
res_list.append(out)
formatted_prompt = reference_system_prompt.format(responses=responses)
return formatted_prompt3. Configure and build the Mixture of Agents pipeline.
Let's configure and build out the whole workflow!
Here is a breakdown of the different components:
CHAT_MEMORY: This is used to store and retrieve the chat history of the workflow.CYCLES: Number of times the input and helper responses are passed through to theLAYER_AGENTLAYER_AGENT: Each agent within this layer agent runs in parallel, and the responses are concatenated using theconcat_responsehelper function.MAIN_AGENT: The final agent that responds to the user's query based on the layer agents
# Hyperparameters of agent
# Re run this if you want to delete chats
CHAT_MEMORY = ConversationBufferMemory(
memory_key="messages",
return_messages=True
)
CYCLES = 3
LAYER_AGENT = ( # Each layer agent in this dictionary runs in parallel
{
'layer_agent_1': RunnablePassthrough() | create_agent(
system_prompt="You are an expert planner agent. Break down and plan out how you can answer the user's question {helper_response}",
model_name='llama-3.3-70b-versatile'
),
'layer_agent_2': RunnablePassthrough() | create_agent(
system_prompt="Respond with a thought and then your response to the question. {helper_response}",
model_name='meta-llama/llama-4-scout-17b-16e-instruct'
),
'layer_agent_3': RunnablePassthrough() | create_agent(
system_prompt="Think through your response step by step. {helper_response}",
model_name='gemma2-9b-it'
),
# Add/Remove agents as needed...
}
|
RunnableLambda(concat_response) # Format layer agent outputs
)
MAIN_AGENT = create_agent(
system_prompt="You are a helpful assistant named Bob.\n{helper_response}",
model_name="llama3-70b-8192",
temperature=0.1,
)Build the mixture of agents pipeline and create the chat function to ask questions to the agents
The chat_stream function takes in a query and passes it through the mixture of agents workflow. The query is:
- Passed through the LAYER_AGENT, which in parallel, generates responses from each of the layer agents and conctenates it using the
concat_responsefunction. - If
CYCLESis more than 1, it passes through again through the LAYER_AGENT, this time with the previous concatenated responses and the user's query. This repeatsCYCLEStimes. - The final layer concatenated response and the user's query is passed to the
MAIN_AGENT, which then stream the final response as and when done.
def chat_stream(query: str) -> Generatorrstr, None, None]:
"""Run Mixture of Agents LCEL pipeline"""
llm_inp = {
'input': query,
'messages': CHAT_MEMORY.load_memory_variables({})o'messages'],
'helper_response': ""
}
for _ in range(CYCLES):
llm_inp = {
'input': query,
'messages': CHAT_MEMORY.load_memory_variables({})o'messages'],
'helper_response': LAYER_AGENT.invoke(llm_inp)
}
response = ""
for chunk in MAIN_AGENT.stream(llm_inp):
yield chunk
response += chunk
# Save response to memory
CHAT_MEMORY.save_context({'input': query}, {'output': response})4. (Optional) Add observability to view your Agent's execution
We can optionally use Arize Phoenix to trace and evaluate the execution of our agent. Phoenix can be run locally or in the cloud. We'll use a local instance to keep things simple.
! pip install arize-phoenix openinference-instrumentation-langchain
from openinference.instrumentation.langchain import LangChainInstrumentor
import phoenix as px
from phoenix.otel import register
session = px.launch_app()
tracer_provider = register()
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
session.view()
5. Chat with the Agent
Let's chat with our mixture of agents!
# Chat with Agent
while True:
inp = input("\nAsk a question: ")
print(f"\nUser: {inp}")
if inp.lower() == "quit":
print("\nStopped by User\n")
break
stream = chat_stream(inp)
print(f"AI: ", end="")
for chunk in stream:
print(chunk, end="", flush=True)Conclusion
In this notebook we demonstrated how to build a fairly complex agentic workflow using Groq's fast AI inference. MoA and other agentic workflows offer significant advantages in working with Large Language Models (LLMs). By enabling LLMs to "think," refine their responses, and break down complex tasks, these approaches enhance accuracy and problem-solving capabilities. Moreover, they present a cost-effective solution by allowing the use of smaller, open-source models in combination, even when multiple LLM calls are required. This notebook serves as an introduction to agentic workflows and in production, should be adapted to your use case and evaluated thoroughly.
For a more Object Oriented approach, StreamLit demo app, and an easier way to configure the workflow please checkout this repo.